DeepSeek革命性的开源多模态AI模型,集成先进的文本生成图像和视觉理解能力。性能超越DALL-E 3,DPG-Bench准确率达84.2%,提供1B和7B两种版本灵活部署。

功能与特性
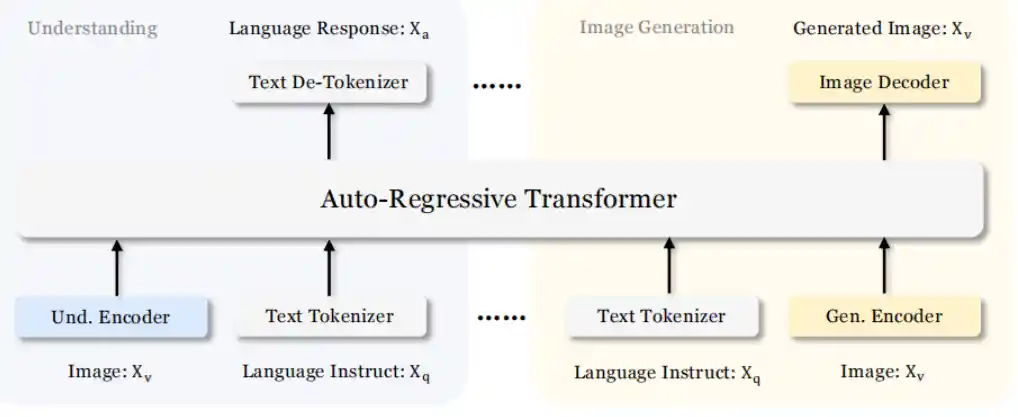
- 多模态理解与生成
- 支持从文本生成图像(文本到图像)。
- 能理解和处理图像内容,对图像进行解析并生成相关的文本或标签。
- 支持图像到文本的指令跟随,可根据图像内容生成文本描述。
- 开源与大规模模型
- 提供1B和7B两种规模的模型,适配多元应用场景。
- 开源特性,开发者和研究人员可自由使用并进行二次开发。
- 改进的训练策略与数据集
- 采用优化的训练策略,提升多模态任务的稳定性和效率。
- 使用大规模、多样化的训练数据集,覆盖广泛场景,提升模型的理解能力和生成质量。
- 解耦视觉编码路径
- 视觉编码解耦,避免视觉和语言信息处理中的冲突,提升模型的灵活性和扩展性。
- 高效的图像生成能力
- 在文本到图像的生成任务中表现出色,生成图像具有高真实性和细节。
- 支持动态分辨率,灵活适应384px到4K的输入大小。
- 多任务学习与推理
- 支持多任务学习,可同时处理图像生成、图像理解、跨模态推理等多种任务。
- 推理能力强,在多个领域和任务中提供准确结果。
- 企业级特性
- 提供军事级AES-256加密,符合HIPAA/SOC2标准。
- 支持本地、云端和边缘部署,最低24GB显存即可运行。
- 提供定制适配器,适用于医疗、创意和技术领域。
强大之处
- 卓越的性能表现
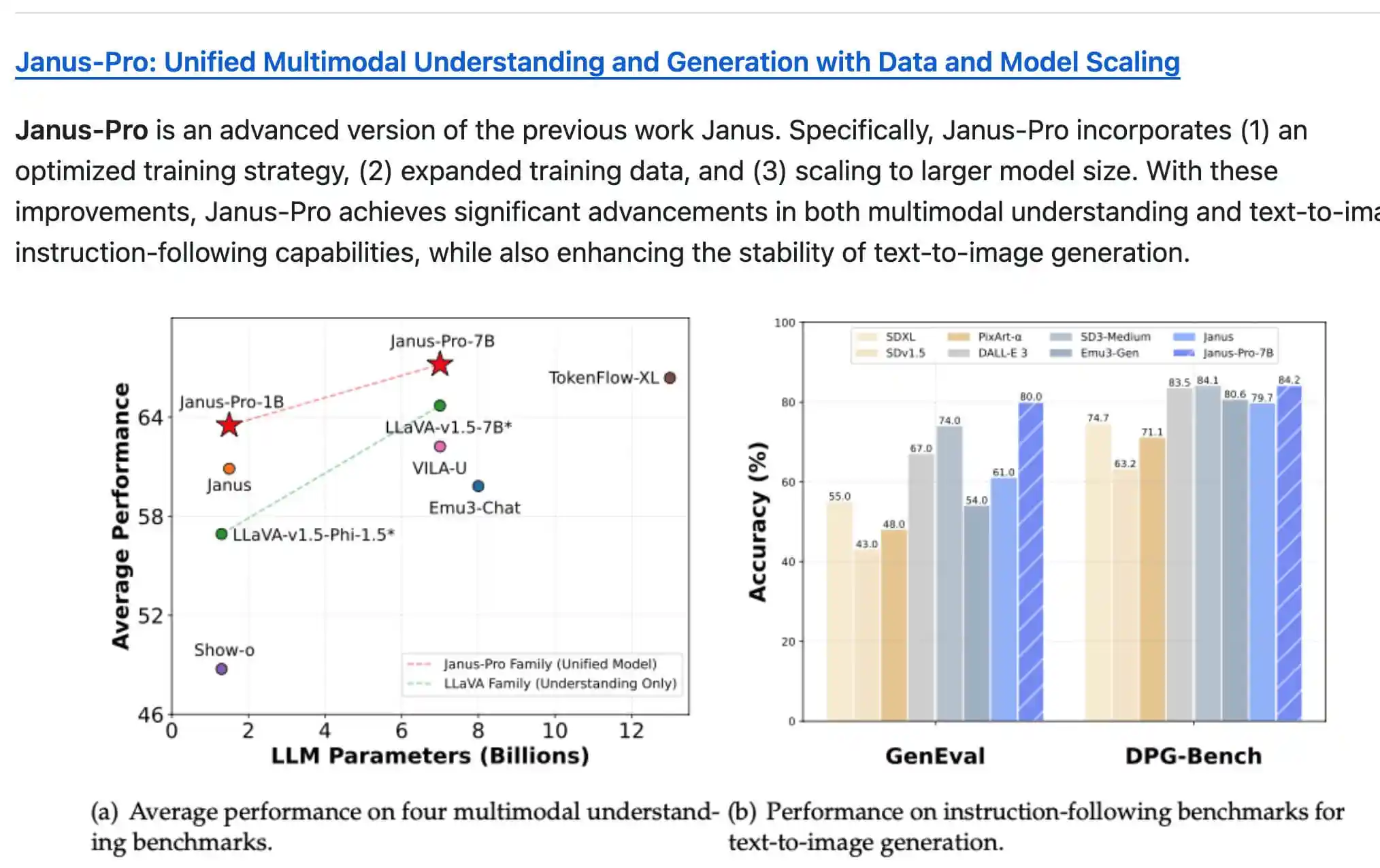
- 在多模态理解任务(如MMBench)中,Janus-Pro-7B的准确率达到79.2,超越其他竞品。
- 在文本到图像生成任务(如GenEval)中,准确率高达80%,显著优于DALL-E 3和Stable Diffusion。
- 在DPG-Bench基准测试中,得分达到84.19,证明其在复杂指令执行和高质量图像生成方面的强大能力。
- 高性价比
- 每次请求仅需0.003美元,比GPT-4V等竞品便宜40倍。
- 操作成本比其他解决方案低92%,适合大规模商业应用。
- 广泛的应用场景
- 适用于广告设计、游戏开发、艺术创作、教育、社交媒体内容生成和视觉故事板制作。
- 在汽车设计、电商和医疗研究等领域也有成功案例,例如加速汽车概念设计和生成医学影像。
- 灵活的部署与支持
- 提供5年模型更新和专业的机器学习工程支持。
- 支持多云平台(AWS、GCP、Azure)和本地部署,满足不同企业需求。
- 高质量的生成能力
- 图像生成质量高,FID评分为8.53,CLIP分数达到0.89,生成图像更符合人类偏好。
- 支持16张图像同时生成,满足多样化的创意需求。
相关链接
- 代码链接:https://github.com/deepseek-ai/Janus
- 模型链接:https://modelscope.cn/collections/Janus-Pro-0f5e48f6b96047
- 体验页面:https://modelscope.cn/studios/AI-ModelScope/Janus-Pro-7B
- 技术报告:https://github.com/deepseek-ai/Janus/blob/main/janus_pro_tech_report.pdf
- Janus-Pro节点组作者开源的项目地址:github.com/deepseek-ai/Janus?tab=readme-ov-file#janus
- 模型下载地址:github.com/deepseek-ai/Janus?tab=readme-ov-file#janus
- 详细部署:https://mp.weixin.qq.com/s/CiWvmL9W6GGJBnok2YJU8A
- 在线体验:https://janus-deepseek.com/zh#feature