DeepSeek R1 模型在AI领域引起了广泛关注,许多人好奇:它到底牛在哪里?本文将从推理能力、性价比、开源灵活性等多个角度为你揭开DeepSeek R1的强大之处。
卓越的推理能力:超越传统与同行
国际主流模型
| 模型系列 | 性能表现 | 应用场景 | 优势 | 局限 |
|---|---|---|---|---|
| OpenAI的GPT系列 | 1750亿参数,处理多种自然语言任务,如文本生成、机器翻译等 | 智能客服、内容创作、语言翻译 | 强大的语言生成能力,高质量文本输出 | 计算资源消耗大,训练成本高 |
| Anthropic的Claude系列 | 快速、能干的助手,覆盖自然语言处理、机器翻译等 | 复杂文本处理,如法律文件翻译 | 对复杂文本和语境的理解能力强 | 在特定领域表现不如专业模型 |
| Google的Gemini系列 | 多模态支持,长上下文处理,语言理解和生成出色 | 智能教育、虚拟助手 | 多模态交互,长上下文处理能力强 | 在特定领域表现不如专业模型 |
数学推理:精准而高效
在AIME 2024数学竞赛中,DeepSeek R1取得了79.8%的pass@1得分,略微超过OpenAI的o1-1217模型。在MATH-500基准测试中,它更是以97.3%的高分脱颖而出,与OpenAI-o1-1217性能相当,显著优于其他模型。这表明DeepSeek R1在处理复杂数学问题时,不仅准确率高,而且推理过程高效。
代码推理:专家级表现
在代码竞赛任务中,DeepSeek R1展现了专家级水平。例如,在Codeforces竞赛中,它获得了2029 Elo评级,超过了96.3%的人类参与者。这不仅证明了其在代码生成和优化方面的强大能力,还显示了它在实际编程场景中的实用性。
复杂推理任务:潜力无限
在需要复杂推理的任务(如FRAMES)上,DeepSeek R1表现卓越,凸显了其在AI驱动的搜索和数据分析任务中的潜力。这种能力使其在处理多步骤、多条件的复杂问题时,能够提供高效的解决方案。
高性价比:低成本,高性能
训练成本低
DeepSeek R1的训练成本显著低于OpenAI的模型。数据显示,每100万tokens的输入,R1比OpenAI的o1模型便宜90%,输出价格更是降低了27倍左右。这意味着在相同的预算下,用户可以进行更多的训练和优化。
硬件要求低
与传统模型相比,DeepSeek R1可以在较低性能的机器上运行,这对于小型企业和资源有限的用户来说尤为重要。它降低了硬件门槛,使更多人能够使用这一强大的AI工具。
开源与灵活性:自由与创新的结合
开源特性
DeepSeek R1采用MIT License开源,用户可以自由使用、修改、分发和商业化该模型,包括模型权重和输出。这种开源策略不仅降低了使用成本,还激发了社区的创新活力。
模型蒸馏:小模型,大能力
DeepSeek R1支持模型蒸馏,开发者可以将它的推理能力迁移到更小型的模型中,满足特定场景的需求。通过模型蒸馏,小模型虽然体积小、运算速度快,但表现却能接近大模型,甚至在某些任务上超越顶级模型。
为什么DeepSeek R1的训练成本更低?
DeepSeek R1的训练成本低,主要归功于其采用的聪明技术和策略,让模型既高效又省钱。以下是几个关键因素:
1. 模型结构更聪明
- 稀疏计算设计:DeepSeek R1像“挑选”计算任务,只使用必要的计算资源,大大减少了计算量。
- 改进的注意力机制:优化了传统计算方式,减少计算复杂度,加快训练速度。
- 高效分配资源:根据任务需求,只分配必要的计算资源,避免浪费。
2. 训练方法更有技巧
- 课程学习:从简单任务逐步过渡到复杂任务,让模型更容易学习,减少训练步骤。
- 动态批处理:根据数据长度调整训练批次,最大化利用GPU内存,避免浪费。
- 高效的优化器:使用节省内存的优化器,加速训练,减少显存占用。
3. 数据处理更聪明
- 数据蒸馏:通过筛选或合成数据,减少需要处理的原始数据量,但保持高效的训练效果。
- 清理重复数据:去除无用的重复或噪音数据,加快训练速度。
- 数据复用:对部分数据进行复用,避免重复训练,节省时间。
4. 硬件和技术优化
- 混合并行:结合多种并行计算方式,加快大规模模型训练速度。
- 显存压缩:通过技术手段压缩显存使用,减少模型训练占用的内存。
- 低精度训练:使用低精度计算,减少计算和存储需求,不影响模型效果。
5. 迁移学习和复用
- 增量训练:基于已有的预训练模型进行微调,节省大部分训练成本。
- 冻结部分参数:冻结通用层,只训练与任务相关的部分,进一步降低开销。
6. 算法创新
- 自监督预训练任务优化:设计更高效的预训练任务,提高训练数据利用率。
- 早期退出:对于简单样本,模型提前结束计算,减少计算量,降低训练复杂性。
举个例子
假设传统模型训练需要1000个GPU天,DeepSeek R1通过优化技术可以显著降低成本:
- MoE结构减少40%计算量 → 600 GPU天
- 动态批处理提升20%效率 → 480 GPU天
- 数据蒸馏减少30%训练步数 → 最终需要336 GPU天(成本降低了66%)
小结
DeepSeek R1作为国产AI的杰出代表,其开源特性、低训练成本和强大的应用场景使其具有非凡的意义。它不仅为用户提供了高效、低成本的AI解决方案,还激发了社区的创新活力,推动了国产AI的发展。
满血使用R1的方法
1、集成到自家产品
已经有还有不少大厂官宣部署DeepSeek模型并集成至自家应用的企业,例如百度、360、昆仑万维等;举几个例子,以下几款国产AI都是继承了R1的深度思考到自家产品中使用:
腾旭元宝:yuanbao.tencent.com/chat
360纳米AI:bot.360.com
天工AI:www.tiangong.cn
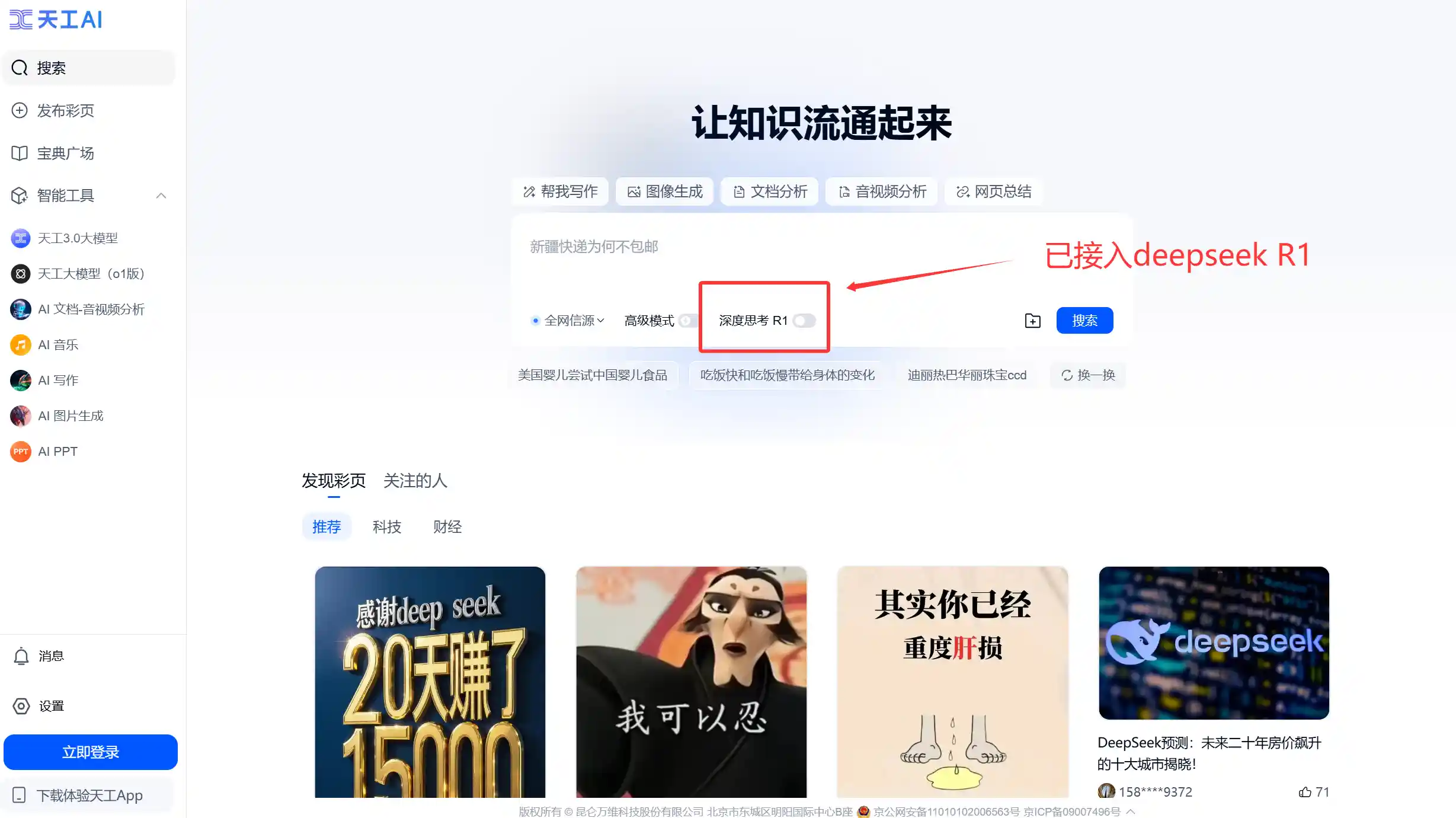
2、大模型平台纯净R1
如果想单独使用纯净的R1,可使用各一些云服务平台的大模型,进入方法大同小异,参考百度的操作步骤:登录后找到模型广场 » DeepSeek R1 » 立即体验:
地址:https://console.bce.baidu.com/qianfan/modelcenter/model/buildIn/list
百度:console.bce.baidu.com
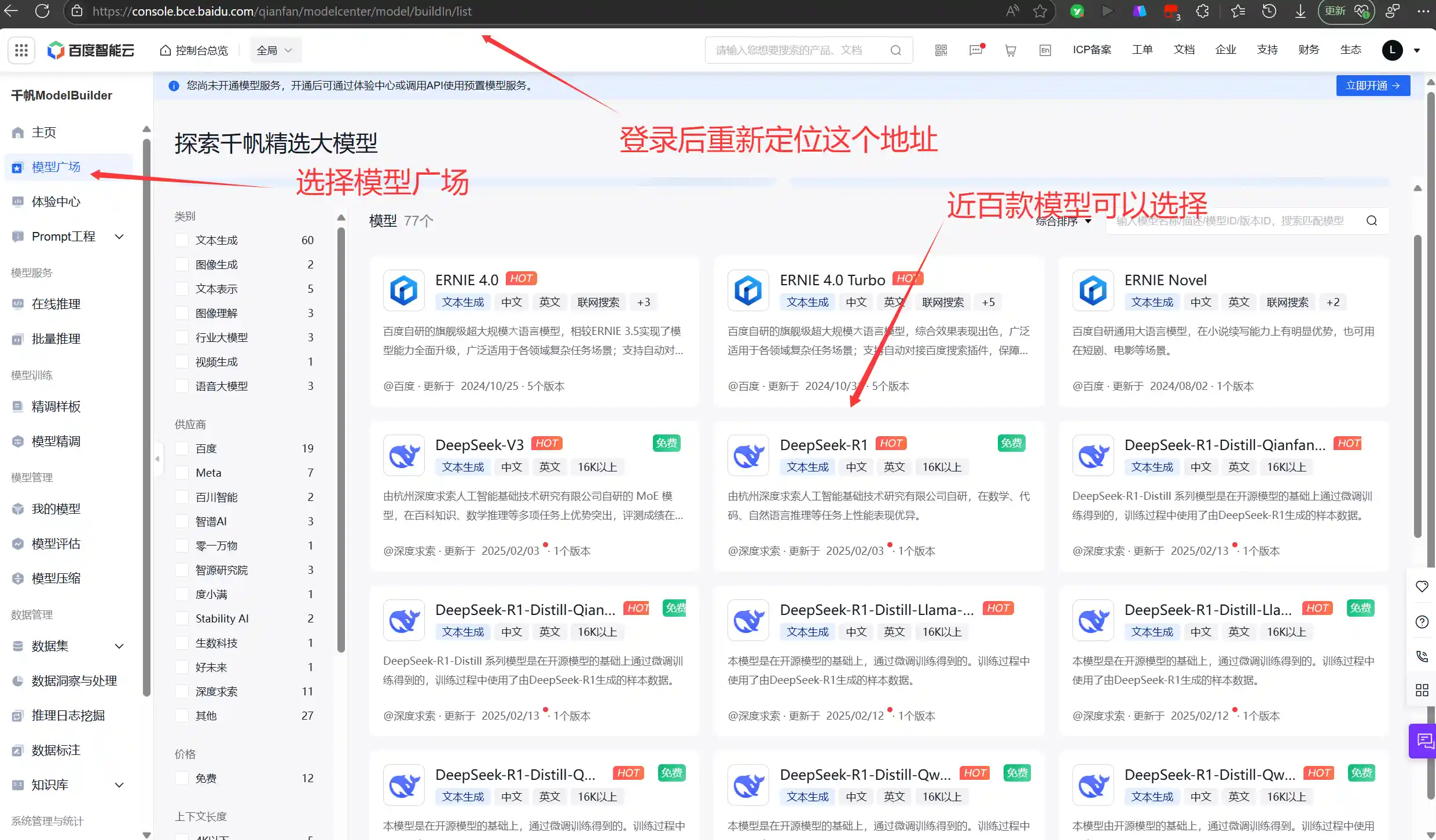
3、集成了R1的第三方免费应用
秘塔AI:https://metaso.cn/
AskManyAI:dazi.co
问小白:wenxiaobai.com
欧派算力云:ppinfra.com
相关资源
官网地址:https://chat.deepseek.com/
【清华大学】DeepSeek从入门到精通: https://pan.baidu.com/s/1FPVXVR9XkswFGMqt_LiTeA?pwd=aiyj