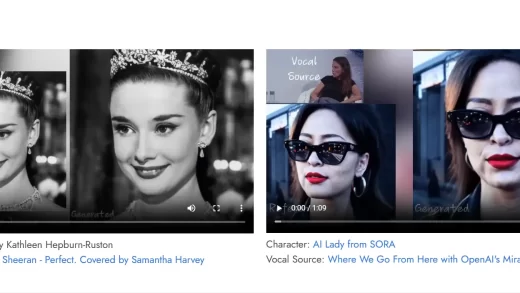
在人工智能的浪潮中,微软亚洲研究院推出了一款令人瞩目的AI模型——VASA-1。这款模型能够将单一的静态图像和语音音频转化为极具逼真度的对话面部动画,开启了人机交互和数字媒体的新纪元。VASA-1以其先进的技术,实现了音频与唇部动作的精确同步,丰富了面部表情,并模拟了自然的头部动作,极大地增强了视频的真实感和生动性。这一技术的发展,预示着人工智能在面部动画和语音合成领域的重大进展。
主要功能和产品特色
- 逼真面部动画:利用语音音频和静态图像生成具有精确唇部运动同步的对话面部视频。
- 自然头部动作:模拟人类交流中的非语言行为,如点头、转头等。
- 实时视频生成:支持在不同模式下高效生成视频,满足实时应用需求。
- 泛化能力:即便面对与训练数据不同的音频或图像,也能保持有效工作。
- 多语言支持:支持中文和多种语言的语音输入,包括生成唱歌动画。
- 解耦能力:独立控制嘴唇运动、表情、眼睛注视方向等面部动态特征。
- 生成可控性:通过条件信号增强视频生成的可控性,允许个性化动画输出。
需求人群
VASA-1适用于娱乐与社交媒体、教育与培训、媒体与广播、安全与监控、广告与营销以及艺术与设计等多个领域,为不同行业的专业人士提供了强大的技术支持。
使用场景示例
- 娱乐与社交媒体:创造逼真的虚拟人物视频,提升娱乐性和互动性。
- 教育与培训:开发虚拟教师或培训角色,提供模拟对话和学习体验。
- 媒体与广播:在新闻播报或视频制作中,生成逼真的发言人或主持人视频。
费用定价
目前,微软尚未公布VASA-1的具体定价策略,但考虑到其前沿技术和潜在的商业应用价值,预计其服务可能会针对不同规模和需求的企业或个人提供定制化的解决方案。
如何使用VASA-1?
鉴于当前的技术敏感性和防止滥用的考虑,微软仅发布了相关论文和演示效果。对于希望体验VASA-1的用户,可以访问以下链接获取更多信息:
- 官网链接:Microsoft VASA-1 Projecthttps://www.microsoft.com/en-us/research/project/vasa-1/
- 论文地址:VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time
关键词标签: